
How Snowflake changes the way we build B2B SaaS products
Snowflake became a game-changing cloud data platform revolutionizing how we build B2B SaaS products.


In March, Snowflake announced its acquisition of the open-source framework Streamlit. Snowflake stock made the deal for $800 million. Streamlit's revenue barely reaches $100,000, and even for the best of times in the SaaS market, the 8,000x multiple looks exorbitant.
Later in May, the company specified its investment vision at the Snowflake Summit 2022 conference in Las Vegas: the framework will become the foundation for developing modern B2B services.
Based on the foundation of a data warehouse, the step to create full-featured applications that can both read and write data to the warehouse seems logical. These modern Software-as-a-Service (SaaS) applications can present materialized views of the data stored in the warehouse. The cloud data warehouse will become an increasingly central part of the SaaS stack, not just the data stack.
But before we dive deeper, let's talk a little bit about Big Data.
Falling Short: The Unfulfilled Potential of Big Data
Tech companies have revolutionized the world economy - with data heralded as an invaluable new commodity. The vast amount of structured and unstructured data generated by organizations and individuals parked energy in tech circles and coined “Big Data.” As a result, the world has quietly moved into the "collect everything" paradigm.
The staggering fortunes inspired the analogy "Data is new oil".The converse, however, is just as plausible; it overlooks how data is obtained, processed, and stored and the complexity of extracting the ultimate benefit. If I could get Amazon's clickstream for 2021, it wouldn't help to create a "better Amazon." Yes, it will help me understand the nature of customer behavior. But it would be more practical for me to sell that dataset to Walmart or Target so they can improve their targeting or recommendations. Tech companies leverage data to generate tremendous financial gains, even when used clumsily. With their extraordinary scale and the power of seemingly minor improvements, this is an area where success can come quickly — unlocking the incredible potential for those who know how best to use it.
Data is not inherently valuable. Thus the notion of the data network effect is overrated regarding value creation. The scale of the data gives an advantage and defensibility to the businesses, but there's nothing about the network effect. Unlike social network effects, each new user only adds to the cost of storing and processing data. Let's imagine a content recommendation product. Yes, viewership logs data help improve machine learning models to promote the content or show ads better. While creating a TikTok clone with a more robust recommendation system would be challenging, the success of the TikTok business is more about the content itself and loops powering author and user engagement.
While “Big Data” has become a buzzword in the media and marketing industry, it is not solely a marketing term. It describes a natural technical challenge organization faces as they try to make sense of the vast amount of data generated. Collecting data isn't the end game. Data by itself is not very useful; we need to figure out how to activate it.
Databases and data warehouses 101
Databases are commonly divided into two types: transactional and analytical. Transactional ones, such as PostgreSQL or MySQL, are used to update, add and delete data. The production database only has data relevant to the app's core operations, like users, business concepts, etc.
Analytical databases are adapted to perform complex queries involving multiple tables.
Companies create and maintain so-called analytical data warehouses (DWH) to provide analysts with access to data. It’s built to handle long, complicated queries written by data scientists, analysts, and machine learning engineers to prepare reports, analyze business processes, and support decision-making systems. A data warehouse is a core component of business intelligence for data analytics and business insights.
Historically, business intelligence has used On-Premise Data Warehouses that relied on massively parallel architecture tools like Teradata, IBM Netezza, or Vertica. Massively parallel processing (MPP) is a class of parallel computing systems. Such systems consist of many nodes, where each node is an autonomous unit independent of the others. If we apply MPP to data storage, the term "distributed databases" best reflects its meaning. Each node in such a distributed database is a complete database management system (DBMS), operating independently of the others. Most importantly, MPP stores demand specialized hardware configured for the processor, storage, and network performance. For example, IBM Netezza comes as separate hardware on dedicated IBM servers.
By the early 2010s, fast-growing IT giants like Facebook, Google, Netflix, LinkedIn, and Airbnb had learned to process vast amounts of data in real-time to support product ecosystems. It turned out that the layer of unstructured data could be helpful for Business Intelligence, but there was no industry consensus on how to process the data. The classic setup for analyzing big unstructured data was that data was stored in HDFS (Apache Hadoop) on the company's servers and processed using the MapReduce paradigm.
While MPP products are limited to hardware, MapReduce and Hadoop are deployed on clusters of standard servers, and the clusters can grow as data volumes increase. At the time, combining the two approaches seemed like a panacea. However, the engineer's job was inefficient: analytics queries took a long time, and they had to combine Hadoop for storing unstructured data and MPP storage for business intelligence.
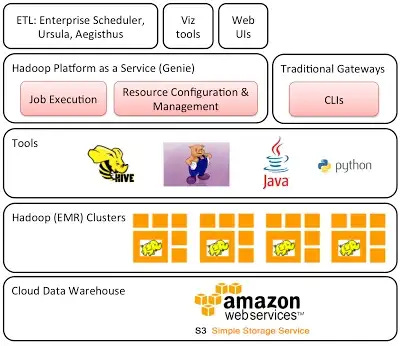
This is an excellent example of how Netflix built its Hadoop Platform as a Service with Teradata in 2011.
At the turn of 2011, the first breakthrough occurred: the MPP database company ParAccel figured out how to run storage on a more affordable infrastructure. One of the company's longtime customers, AWS, copied and adapted the solution to its ecosystem. That's how the cloud data warehouse, Redshift, came about in 2013.
Redshift announced on AWS 2012 re:Invent event.
Redshift simplifies processes by providing a single console for managing all tasks. This makes it easier for developers to focus on their work without worrying about scaling and disaster recovery in the event of failures.
Around the time in Seattle, Google engineers released Dremel, a near-real-time query processing system. Dremel was used for various purposes, such as analyzing documents collected by search bots, tracking app installs in the Android Market, and aiding in Google Books and spam analysis. In 2012, Google made Dremel available to developers through Google BigQuery, which marked the beginning of the Cloud-First Managed Data Warehouse era. Redshift and BigQuery allowed developers to focus on their work without worrying about managing servers and scaling and offered a usage-based pricing model for added convenience. However, managing load on Redshift and BigQuery could be challenging, as it required increasing the cluster for computation and data storage, which often involved redistributing data and resulting in some downtime.
Snowflake: The Game-Changing Cloud Data Platform
When Redshift and BigQuery had been on the market for two years, two ex-Oracle engineers and the founder of Vectorwise brought the new cloud warehouse solution out of stealth mode: Snowflake.
Snowflake is a standout data warehouse solution that offers a range of services beyond competitors like BigQuery and Redshift. Its intuitive user experience and unparalleled scalability make it a top choice for modern businesses. One of the key features that set Snowflake apart is its separation of storage and computing, a revolutionary approach that is reflected in its three-layer architecture:
The data storage layer,
The query processing layer,
Service layer of authentication, metadata, etc.
As Kevin Kwok noted, this is a hallmark of Snowflake’s lead VC and original CEO, Mike Speiser:
When Snowflake Computing was started in 2012, most investors and companies were convinced that in order to sell into large companies you had to support on-premise workloads. Hell, most customers were convinced to sell to them you had to handle on-premise. Betting all-in reminds me of something Reid Hoffman once mentioned about principles. Principles are only principles if you’d hold them even when they are costly. It is only betting fully when it comes at a real cost to the business. For example, in customers that can’t be served because they need a hybrid solution…
* In 2022, a new partnership was announced between Snowflake Inc. and Dell Technologies, bringing Snowflake Data Cloud's tools to on-premises object storage for the first time.
Snowflake is a SaaS product that lives beyond standard infrastructure tasks.
You can scale cloud resources without interrupting running requests.
Scale up your query resources infinitely. Need to run a vast giant massive query? Just create a new virtual warehouse or two. Don’t you need them anymore? Shut them down!
Different users in an organization have various requirements for data usage and workload. With Snowflake, the marketing analytics department will run a long task, and their colleagues will continue to use the product as if nothing had happened. That is, teams will be more productive. This saves a lot of money if the load is uneven during the day or if the system is used only occasionally.
Snowflake does not use its cloud storage but is deployed on AWS, Azure, and GCP. The service cost comprises a fee for the amount of data in S3 and an hourly fee for the virtual servers used. If the client has two virtual clusters of 4 servers, and they were running for 9 hours 3 minutes, you would have to pay for 2×4×10=80 hours of service. Snowflake has an agreement with cloud providers that they get new instances within 5 minutes. Then it takes 1-5 minutes to expand a virtual cluster or create a new one.
Snowflake, though, charges you for a unit called a credit. Each resource in Snowflake – be it storing data, querying it, or using the cloud services around it – costs you in terms of credits per hour. For example, if you’ve set up a virtual warehouse to query your data (recall: this is what Snowflake calls their servers used for computing), and you choose the “X-Small” size, this will cost you one credit per hour if you’re on the standard plan, that comes out to $2/hr, which seems reasonable.
In addition, the cloud-based, serverless model involves much less tuning by the administrator, making it easier to move from managing resources to managing users and their requests.
Snowflake handles tasks that are impossible with the original database design.
Snowflake is a SaaS product that lives within standard infrastructure tasks. For example:
You can do Undrop - recover lost data or even bring versioning to the database.
You can share your dataset with another user. That way, he won't pay for data storage but only for computation. Snowflake’s unique write-ahead micro-partition architecture has helped Snowflake differentiate its offering into a whole (no-copy within a region) Data Cloud where 1000s of 1000s of public, semi-private, and utterly private data sets can be shared.
In addition, you can leverage Marketplace to power up the data collaboration and datasets discovery, like lookup tables (finding zip codes and such), medical data, weather, and public stuff.
No need to worry about data partitioning - breaking up large tables into logical parts. Snowflake determines the logic itself, although it needs to be fine-tuned in some cases.
Snowflake provides you with many different ways to query and access the data you’ve got stored in their systems. Here are a few of the major ones. To reiterate, these aren’t necessarily differentiated from other warehouses. You can access data through Snowflake SDK, through their command line interface.

You might be wondering why Amazon Web Services (AWS) has not chosen to remove Snowflake, a third-party data warehousing service, from its platform to promote its solution.
One reason could be that AWS recognizes the value of offering its customers a range of options, and Snowflake has established itself as a popular choice in the data warehouse market. Additionally, hosting Snowflake on its platform allows AWS to generate revenue through Snowflake's usage.
Snowflake's business operates at a 65% operating margin. Cost structure: 68% Sales and Marketing, 43% R&D.
Let's say a customer pays Redshift $1 million/per year. Redshift's EC2 margins are about 50% of AWS's. So AWS will make ~$500k profit.
When it comes to Infrastructure-as-a-Service (IaaS) solutions, major vendors like AWS and Microsoft Azure don't tend to have a pricing advantage due to their economies of scale – it's ultimately a commodity: there is little difference between a server instance on Azure or AWS; the primary lock-in is the pain of moving and the lower prices that come from scale.
However, when it comes to Platform-as-a-Service (PaaS) providers, the likes of Microsoft, Amazon, and Google may have a price advantage. Snowflake, like Oracle, offers the advantage of being a no-lock-in solution.
Chris Grusz, director of business development for AWS Marketplace, shares the same point in a joint interview with Chris Degnan, chief revenue officer of Snowflake
A commitment to “working backward from the customer” is “in the DNA” of both AWS and Snowflake, according to Grusz. This means that if it is in the customer’s best interest to choose Snowflake over AWS, Snowflake will support that decision.“AWS is our largest cloud in terms of revenue today. They just kind of know how to do it right, and they’ve been a wonderful partner all along,” Degnan said.
And lastly, "serverless" doesn't have to be cheaper. Auto-scaling is a trade-off between price and the desire to manage the load (read: productivity). WeWork switched from Redshift to Snowflake, paying almost 2x, but engineers were exhilarated with Snowflake.
Go-to-market strategy
By 2023, it no longer takes months to build an analytics stack. Large amounts of data can be uploaded to cloud storage and up and running in a few days. Moreover, the SaaS business model lowers the entry threshold into data engineering: you don't need a thorough understanding of monolithic technologies like Hadoop, Spark, Teradata, Informatica, Vertica, and the theory of distributed computing and data storage.
Snowflake had its most expensive public offering in 2020. The IPO was so successful that even Warren Buffett changed his principle of not participating in IPO deals and invested in Snowflake (which allowed the investor to make $800 million rather quickly).
By this point, Snowflake had impressive stats:
$532 million Annualized Run-Rate Revenue (ARRR) with a YoY growth rate of 121%.
146 Fortune 500 companies and 3,117 customers, including Doordash, Square, Adobe, Instacart, Sony, and Sega.
The average customer paid ~$160k, which is quite a lot for a public SaaS company. The number of customers with $1M is 56, YoY growth: of 154%.
As of April 2022, according to Q1 2022, Snowflake has 6,300 customers, 206 of them paying over $1M/year, NDR 177%.

A popularity trend of data storage vendors. https://db-engines.com/en/ranking_trend
Snowflake uses a combination of direct sales, partnerships, and self-service to market its services. This includes directly reaching out to potential customers and building relationships with partners such as consulting firms or system integrators. Snowflake's cloud-agnostic nature also helps attract enterprise customers, particularly in the banking and retail industries, who are unwilling to cooperate with AWS due to their affiliation with Amazon.
Exploring the Snowflake Ecosystem
While Big Data was evolving from a buzzword on boards to a substantial technology, data engineers were becoming data-obsessed programmers: no longer infrastructure, but modeling, primary processing, and more.
Based on the documentation, partner connect is a way to get free trials of related software like dbt or Domo, while automatically integrating those accounts into Snowflake.
Data warehouses have inherently large lifetime values, given that the data, once imported, isn’t going anywhere, but the ecosystem only reinforces the dynamic. Five years ago, it seemed that the entire data tools market would be consolidated by the leading cloud vendors: Google Cloud, Azure, and AWS. Companies were trying to create tools for the entire data supply chain, from data offloading (ETL/ELT) to visualization and machine learning.

However, the popularity and no-lock-in advantages of Snowflake and Databricks have changed the market and made it more fragmented. Today, engineers can quickly replace one tool with another with minimal vendor lock. Snowflake quickly began scaling a partner network, seamlessly integrating other products to work with data from the application interface. With a click, a virtual machine for your favorite data-engineering product is created under you, and access parameters are emailed to you. Partners can take advantage of what Snowflake delivers in the data cloud and focus on building domain-specific capabilities. They're able to go to market much faster, but also to market in multiple clouds, in various regions, without needing to take on a lot of overhead because we support that built-in.
As a result, Snowflake realizes they have an incredible resource. So the next logical step for them is to make the abstract bits of information work for the business's good. The more value Snowflake's customer sees from the accumulating data, the longer they stay on the platform.
The future of Snowflake: Streamlit, Native Application Framework, Unistore
Streamlit is an open-source Python library. It makes it easy to create beautiful web applications for machine learning engineers - in just a few minutes and a couple of lines of code. Data can be visualized easily, and dashboard controllers directly change Python variables.

At the Snowflake Summit 2022 conference in Las Vegas, the company unveiled two products that paved the Streamlit purchase - the Native Application Framework and Unistore. The Native Application Framework allows providers to build applications using Snowflake functionality. Unistore is an attempt to extend Snowflake's arsenal to application writing. Not much is known yet, other than the global vision for building a repository: it can be used for analytics and product backend support. The idea is not new; Gartner Inc. coined the term Hybrid transactional/analytical processing in its early 2014. The main technical challenges for an HTAP database are how to be efficient both for operational (many small transactions with a high fraction of updates) and analytical workloads (large and complex queries traversing large numbers of rows) on the same database system and how to prevent the interference of the analytical queries over the operational workload.
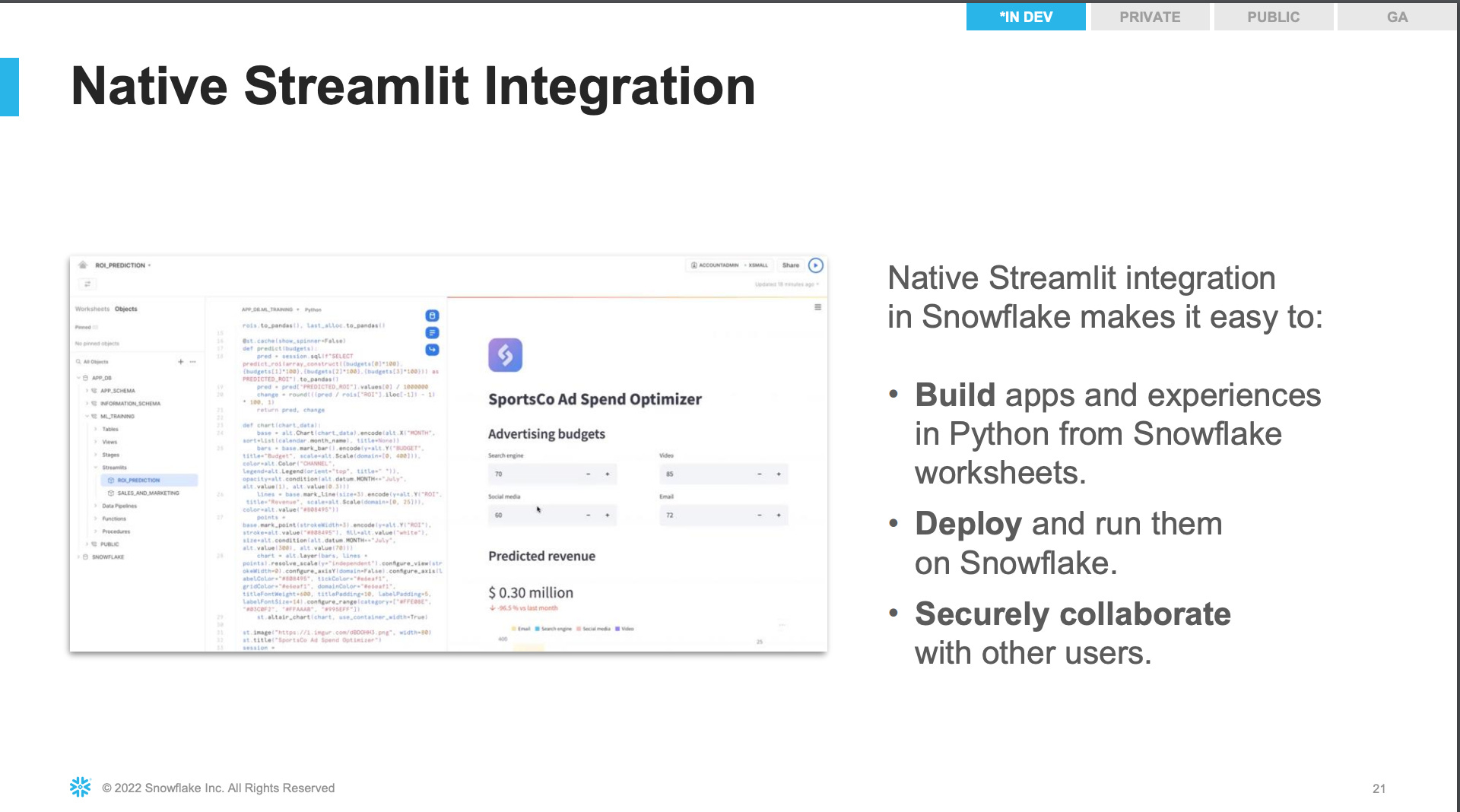
I like Benn's metaphor here – running apps inside a database could change the notion of a database - in the same way that the iPhone changed the notion of phones. Data-app in the Snowflake ecosystem is still too generalized a concept; it's a tool for ETL, some clever ML algorithm for ribbon clustering, a data visualization tool and an algorithm for email segmentation, and even an entire CDP platform.
The main idea around which this evolution is being built is the democratization of the value of data for everyone in the company.
In the last six months, I have met the founders of companies making applications on top of Snowflake.
Vero and Supergrain are building an alternative to Mailchimp on Snowflake. Personally, the tools have provided me with a convenient segmentation of users based on what they do in the product.
Hunters and Panther help companies get away from Splunk and build their SIEM directly on Snowflake.
Calixa and Heads Up provide additional product domain analytics for B2B startups. It's partly a foray into CDP territory.
Eppo helps do and analyze A/B experiments.
Avenue does operational analytics.
Some might say, "Come on; it's just a connector in DWH and data-layer integration via a driver and some SQL queries." Yes, that's the case so far. But that's why Snowflake is buying Streamlit.
For a B2B-SaaS founder, you get a set of components or an entire framework. I'll draw parallels with web development. Django, Ruby-on-Rails components cover the basic needs: how to connect to the database, validate the form, and so on. To describe the logic, you need a language other than SQL. Streamlit in this system becomes not just a framework for writing data applications but a platform language like Swift or Kotlin.

Snowflake's native application framework allows developers to package code or data using various tools, such as stored procedures, tasks, streams, and user-defined functions (UDFs), and deploy it using the low-code user experience framework Streamlit. I propose to think of no-code as a code generator that generates code integrated into all modern engineering practices: CI/CD, PR, and others. This allows developers to easily create and deploy applications without worrying about operational complexity and data security, as Snowflake handles these aspects. The framework includes an "installer" stored procedure that can create application-related objects in a separate schema, such as tables and views. Customers can customize the installer process to create different objects based on parameters, which enables developers to charge customers based on the features they use. If a customer does not have a Snowflake account, an application developer can provide them with a read-write performance and charge them for access.

Maybe AWS, Oracle, or Google solutions will come along, and we'll need cross-vendor frameworks. We may see competition from data-lake vendors or vendors of popular OLTP databases.
For developers, the platform is still in beta. And after the presentation, there are questions about the parallelism of UDF or the isolation level of Unistore. When a company pays $160K annually for Snowflake, giving another $12K for your product is much easier. Security is a big selling point → data never leaves your warehouse. Depending on the functionality requirements, some SaaS companies could be rebuilt as native apps.
Bonus
Let’s make this a bit more tangible and design a CRM system on Snowflake to see why it makes sense. From personal practice, I would say there is no convenient CRM system for B2B SaaS self-service businesses. Classic CRM is built around transactions, but in self-service, it is essential to "grow" the contact to connect a Sales specialist at a certain point.
Moritz is likely unaware that the original tweet motivated the author to write this issue
I utilize various methods to import (reverse-ETL) product usage data into Hubspot, including a custom microservice that listens for webhooks, workflow automation tools, and data warehouse orchestrators."
Let's imagine that CRM uses Snowflake as the backend. I can implement the core functions using existing drag-and-drop modular components, visualization elements, forecasting, alerting, etc. For basic CRM entities (contacts, deals, companies), tables are created in Snowflake via Unistore. CRM may maintain a separate database of their data containing application state, user permissions, and other metadata. Still, increasingly, the core data used to course through a system of record will be pushed/copied to the DWH.
For a data scientist to make forecasts, there is no need to upload data to the notebook; you can take Streamlit and build the necessary experience within the application. Any alerting logic can be described declaratively. An application or workflow can be created depending on its interaction with the product. The customization limits are almost limitless.
Storing data in a central repository makes integration easier: information on Google Ads, Facebook Ads, Stripe, Zendesk, Intercom, and Mixpanel is already available in CRM. We might still need to use ETL / Reverse-ETL since we need tools responsible for consolidating application data into the Snowflake repository.
I’m convinced this new architecture and the Snowflake framework will shake up the SaaS ecosystem in a big way. Snowflake has a solid customer base and a thriving community of data professionals vouching for their warehouse services, and they won’t have problems hosting a good number of applications on their marketplace.